The summary of 0.1° ACCESS-OM2-01 IAF outputs has been updated to include the 4th cycle and its extension, which include extensive BGC data.
COSIMA offers PhD Top-up Scholarships for Ocean and Sea Ice Modelling valued $7,500 per year
PhD Top-up Scholarships for Ocean and Sea Ice Modelling
Are you interested in understanding ocean physics, and do you have skills in computational/mathematical modelling?
The Consortium for Ocean-Sea Ice Modelling in Australia is providing opportunities for PhD students to work at the intersection of high-performance computing and ocean-climate dynamics. Projects are available focusing on a wide range of topics, including:
- The role of sea ice in the climate system;
- Modelling biogeochemical cycles in the global ocean;
- Coupling between surface waves and large-scale currents;
- Antarctic ice shelves and their interaction with the Southern Ocean; and
- The sensitivity of ocean dynamics to vertical coordinate systems in ocean models.
These scholarships are valued at $7,500 per year for 3.5 years. Successful applicants will also need to be successful in receiving a Research Training Program (RTP) scholarship, or equivalent primary scholarship, at a COSIMA partner university (ANU, UNSW, UTas, USyd, UniMelb or U Adelaide).

To Apply, you should submit a package to Ms Alina Bryleva including:
- A half-page statement explaining your research interests and your planned work with COSIMA.
- Your CV and academic transcripts.
- Provide amount and source of any existing scholarships, both top-ups and a primary stipend.
These top-up scholarships are intended primarily for new students, however existing students working on one of the COSIMA models will also be considered. Preference will be given to competitive applicants who do not already receive a top-up scholarship from another source.
Enquiries: Please contact Professor Andrew Hogg Andy.Hogg@anu.edu.au
Closing date: 30 November 2021
COSIMA searching for a new software engineer
Come and work for COSIMA! This is an opportunity for a software engineer to work at the cutting edge of computer science and ocean-sea ice modelling:
Please contact Andy Hogg for details.
Ekman Streamfunction Paper Submitted
The global ocean overturning circulation is the planetary-scale movement of waters in the vertical and north-south directions. It is the principal mechanism by which the oceans absorb, sink, and redistribute heat and carbon from the atmosphere, thereby regulating Earth’s climate. Despite its importance, it is impossible to observe directly, and must be inferred from sparse and infrequent proxy measurements. The main upward branches of the overturning circulation are located in the Southern Ocean, where strong westerly winds upwell waters from below. Thus, changes in these westerly winds will lead to changes in the overturning circulation, and, subsequently, Earth’s climate.
In a recently submitted paper, we introduce a new tool that we call the Ekman streamfunction to analyse the change of the winds in a framework that is directly comparable with the overturning circulation. We test the Ekman streamfunction with model output from ACCESS-OM2-01 in which the overturning circulation is measured directly. We find throughout much of the Southern Ocean, the Ekman streamfunction provides a robust indicator of the strength and variability of the overturning circulation, with exceptionally high correlation. Our new tool provides a novel approach for reexamining existing datasets of winds measured from satellites, to infer recent changes in the overturning circulation.
“The Ekman Streamfunction: a wind-derived metric to quantify the Southern Ocean overturning circulation”; Stewart, Hogg, England, Waugh & Kiss, Submitted to Geophysical Research Letters.
Unreviewed submission available here: https://www.essoar.org/doi/abs/10.1002/essoar.10506547.1
Technical Working Group Meeting, December 2020
Minutes
Date: 9th December, 2020
Attendees:
-
Aidan Heerdegen (AH) CLEX ANU
- Andrew Kiss (AK) COSIMA ANU
- Angus Gibson (AG) RSES ANU
-
Russ Fiedler (RF) CSIRO Hobart
-
Rui Yang (RY) NCI
-
Nic Hannah (NH) Double Precision
- Peter Dobrohotoff (PD) CSIRO Aspendale
Testing with spack
NH: Testing spack. On lightly supported cluster. Installed WRF and all dependencies with 2 commands. Only system dependency was compiler and libc. Automatically detects compilers. Can give hints to find others. Tell it compiler to use for build. Can use system modules using configuration files. AH: Directly supported modules based on Lmod. Talked to some of the NCI guys about Lmod, as the raijin version of modules was so out of date. C modules has been updated, so they installed on gadi. Lmod has some nice features, like modules based on compiler toolchain. Avoids problem with Intel/GNU subdirectories that exist on gadi. NCI said they were hoping to support spack, by setting up these configs so users could spack build things. Didn’t happen, but would have been a very nice way to operate to help us.
NH: Primary use case in under supported system where can’t trust anything to work. Just want to get stuff working. Couldn’t find an MPI install using latest/correct compiler. gadi well maintained. See spack as a portability tool. Containment is great.
AH: Was particularly interested in concretisation, id of build, allows reproducibility of build and identification of all components.
NH: Rely on MPI configured for system. Not going to have our own MPI version. AH: Yes. Would be nice if someone like Dale made configs so we could use spack. Everything they think is important to control and configure they can do so. Probably not happy with people building their own SSL libraries. Thought it would improve NCI own processes around building software. Dale said he found the system a but fragile, too easy to break. When building for a large number of users they weren’t happy with that. Thought it was a great idea for NCI, to specify builds, and also easy to create libraries for all compiler toolchains programmatically.
AG: Haven’t tried recently.
Parallel compression of netCDF in MOM5
RY: Continuation of previous PIO work, including compression as now supported by netCDF. Used FMS IO benchmark test_mpp_io to tune parameters. 174GB -> 74 GB with level 4 deflation. Tested two PE numbers. Tested two schemes ROMIO and OPMIO. v1.10.x lots of errors. v.12.x much better. Only had to change deflate_level in mpp_io_nml namelist, no source code changes.
RY: Best settings, for 720 PE, (48,15), best IO layout (24,15), and 1440PE (48,30) best IO layout 12,30. Non-compressed match chunk size with layout. Best time keep x contiguous when compression turned on. Memory access dominate, so layout continuous. Hence x-axis continuous.
RY: Stripe count affects non-compressed more than compressed. PIO doesn’t work perfectly with Lustre, fails with very large stripe count. With large file sizes (2TB) can be faster to write compressed IO due to less IO time.
- Large measurement variability in IO intensive benchmark as affected by IO activity. Difficult to get stable benchmark.
- Use HDF5 1.1.12.x, much more stable.
- Use OMPIO for non-compressed PIO
- Similar performance between OMPIO and ROMIO for compressed performance
RY: Early stage of work. Many compression libraries available. Here only used zlib. Other libraries will lead to smaller size and faster compress times. Can be used as external HDF filter. File created like this requires filter to be compiled into library.
NH: How big is measurement variability? RY: Can be very different, took shortest one. Sometimes double. TEST_MPP_IO is much more stable. Real case much less so.
NH: Experiencing similar variability with ACCESS model with CICE IO. Anything we can do? Buffering? RY: Can increase IO data size and see what happens. Thinking it is lustre file system. More stripe counters touches more lustre servers. Limit to performance as increase stripe counters, as increase start to get noise from system. NH: What are the defaults, and how do you set stripe counters? RY: Default is 1, which is terrible. Can set using MPI Hints, or use lfs_setstripe on a directory. Any file created in that directory will use that many stripe counters. OMPIO and ROMIO have different flags for setting hints. Set stripe is persistent between reboots. Use lfs_getstripe to check. AH: Needs to be set to appropriate value for all files written to that directory.
NH: Did you change MPI IO aggregators or aggregator buffer size. RY: Yes. Buffer size doesn’t matter too much. Aggregator does matter. Previous work based on raijin with 16 cores. Now have 48 cores, so experience doesn’t apply to gadi. Aggregator default is 1 per node for ROMIO. Increase aggregator, doesn’t change too much, doesn’t matter for gad. OMPIO can change aggregator, doesn’t change too much.
NH: Why deflate level 4? Tried any others? RY: 4 is default. 1 and 4 doesn’t change too much. Time doesn’t change too much either. Don’t use 5 or 6 unless good reason as big increase in compression time. 4 is good balance between performance and compression ratio.
NH: Using HDR 5 c1.12.x. With previous version of HDF, any performance differences? RY: No performance difference. More features. Just more stable with lustre. Using single stripe counter both work, as soon as increase stripe counter v1.10 crashes. Single stripe counter performance is bad. Built my own v1.12 didn’t have problem.
NH: Will look into using this for CICE5. AH: Won’t work with system HDF5 library?
AH: Special options for building HDF5 v1.12? RY: Only if you need to keep compatibly with v1.10. Didn’t have any issues myself, but apparently not always readable without adding this flag. Very new version of the library.
AH: Will this be installed centrally? RY: Send a request to NCI help. Best for request to come from users.
AH: Worried about the chunk shapes in the file. Best performance with contiguous chunks in one dimension, could lead to slow read access for along other dimensions. RY: If chunks too small number of metadata operations blow out. Very large chunks use more memory and parallel compression is not so efficient. So need best chunk layout. AH: Almost need a mask on optimisation heat map to optimise performance within a useable chunk size regime. RY: Haven’t done this. Parallel decompression is not new, but do need to think about balance between IO and memory operations.
RF: Chunk size 50 in vertical will make it very slow for 2D horizontal slices. A global map would require reading in the entire dataset. RY: For write not an issue, for read yes a big issue. If include z-direction in chunk layout optimisation would mean a large increase in parameter space.
AH: Optimisation based on performance from simpler benchmark. Numbers didn’t correlate that well with more complex benchmark due to being a much larger file. Would running the benchmark with a larger file change the layouts used for the real world test? RY: Always true that chunk size along x should be contiguous. Probably y chunk size would change with real world example. Trends are the same. Default chunk layout slices all 3 axes. Best performance is always better than default chunk layout.
AH: Larger core counts now around 10K cores. RY: Have to select correct io_layout. Restricts the number of PEs. AH: This is an order of magnitude larger. RY: Filesystem has limited number of IO server. This sets the maximum number of IO PEs. Should always keep number of IO server less than this.
ACCESS-OM-01 runs
NH: AK has been running 0.1 seeing a lot of variation in run time due to IO performance in CICE. More than half the submits are more than 100%worse than the best ones. Is this system variability we can’t do much about? Also all workers are also doing IO. Don’t have async IO, don’t have IO server. Looking at this with PIO. Have no parallelism in IO so any system problem affects our whole model pipeline. RY: Yes IO server will mean you can send IO and continue calculations. Dedicated PE for IO. UM has IO server. NH: Ok, maybe go down this path AH: Code changes in CICE? NH: Exists in PIO library. Doesn’t exist in fortran API for the version we’re using. Does exist for C code. On their roadmap for the next release. A simple change to INIT call and use IO servers for asynchronous IO. Currently uses a stride to tell it how many IO servers per compute. AH: Are CICE PEs aligned with nodes? Talked about shifting yam, any issues with CICE IO PEs sharing nodes with MOM. NH: Fastest option is every CPU doing it’s own IO. Using stride > 1 doesn’t improve IO time. RY: IO access a single server, doesn’t have to jump to different file system server. There is some overhead when touching multiple file system servers when using striping for example.
AH: Run time instability too large? AK: Variable but satisfactory. High core count for a week. 2 hours for 3 months. AH: Still 3 month submits? AK: Still need to sometimes drop time step. 200KSU/year. Was 190KSU/year, but also turned off 3D daily tracer output. AH: More SUs, not better throughput? AK: Was hitting walltime limits with 3D daily tracer output. Possibly would work to run 3 months/submit with lower core count without daily tracers.
AK: Queue time is negligible. 3 model years/day. Over double previous throughput. Variability of walltime is not too high 1.9-2.1 hours for 3 months. Like 10% variability.
AH: Any more crashes? Previously said 10-15% runs would error but could be resubmitted. AK: Bad node. Ran without a hitch over weekend. NH: x77 scratch still an issue? AK: Not sure. AH: Had issues, thought they were fixed, but still affected x77 and some other projects. Maybe some lustre issues? AK: Did claim it was fixed a number of times, but wasn’t.
Tripole seam issue in CICE
AH: Across tripole seam one of the velocity fields wasn’t in the right direction, caused weird flow. AK: Not a crash issue. Just shouldn’t happen, occurs occasionally. The velocity field isn’t affected, seen in some derived terms, or coupling terms. Do sometimes get excess shear along that line. RF: There is some inconsistencies with how some fields are being treated. Should come out ok. Heat fluxes slightly off, using wrong winds. They should be interpolated. What gets sent back to MOM is ok, aligned in the right spot. No anti-symmetry being broken. AK: Also true for CICE? RF: Yeah, winds are being done on u cells correctly. Don’t think CICE sees that. AH: If everything ok, why does it occur? RF: Some other term not being done correctly, either in CICE or MOM. Coupling looks ok. Some other term not being calculated correctly.
AH: How much has our version of CICE changed from the version CSIRO used for ACCESS-ESM-1.5 NH: Our ICE repo has full git history which includes the svn history. Either in the git history or in a file somewhere. Should be able to track everything. Can also do a diff. I don’t know what they’ve done, so can’t comment. Have added tons of stuff for libaccessom2. Have back-ported bug fixes they don’t have. We have newest version of CICE5 up to when development stopped which include bug fixes. As well as CICE6 back ports. AH: Can see you have started on top of Hailin’s changes. NH: They have an older version of CICE5, we have a newer version which includes some bug fixes which affect those older versions.
RF: Also auscom driver vs access driver. Used to be quite similar, ours has diverged a lot with NH work on libaccessom2. We do a lot smarter things with coupling, with orange peel segment thing. There is an apple and an orange. We use the orange. NH: Only CICE layout they use is slender. They don’t use special OASIS magic to suppler that. Definitely improves things a lot in quarter degree. Our quarter degree performance a lot better because of our layout. AH: The also have 1 degree UM, so broadly similar to a quarter degree ocean. NH: Will make a difference to efficiency. AH: Efficiency is probably a second order concern, just get running initially.
Improve init and termination time
AH: Congratulations to work to improve init and termination time. RF: Mostly NH work. I have just timed it. NH: PIO? RF: Mostly down to reading in restart fields on each processor. Knocked off a lot of time. A minute or so. PIO also helped out a lot. Pavel doing a lot of IO with CICE. Timed work with doing all netCDF definitions first and then the writing, taking 14s including to gather on to a single node and write restart file. The i2o.nc could be done easily with PIO. Also implemented same thing for MOM, haven’t submitted that. Taking 4s there. Gathering global fields is just bad. Causes crashes at the end of a run. There are two other files, cicemass and ustar do the same thing, but single file, single variable, so don’t need special treatment.
RF: Setting environment variable turns off UCX messages. Put into payu? Saves thousands of lines in output file.
COSIMA Linkage Project funded
The Australian Research Council (ARC) recently announced $1.1M of funding for a new 4-year COSIMA project. The new project is funded under the ARC’s Linkage Project scheme, and is supported by 4 industry partners: The Department of Defence, Bureau of Meteorology, Australian Antarctic Division and CSIRO. This funding will continue to support the Australian ocean and sea ice modelling community to develop and distribute open source model configurations.
The aims of the proposal are to:
- Configure, evaluate and publish the next-generation MOM6 ocean model and CICE6 sea ice model, culminating in a new, world-class Australian ocean-sea ice model: “ACCESS-OM3”;
- Advance Australian capacity to model the ocean’s biogeochemical cycles and surface waves, including the feedback between waves, sea ice, biogeochemistry and ocean circulation; and
- Build on the success of COSIMA to establish deep ties between Australia’s leading ocean-sea ice modelling institutions, while maintaining ACCESS-OM2 for ongoing research projects and operational products.
Work on the new project is expected to begin in 2021, initially focussing on the adoption of the MOM6 ocean model for regional applications. A schematic of the intended workflow can be found in the figure below.

As well as developing new model configurations, the new COSIMA project will have a stronger emphasis on developing tools for data analysis, data sharing and publication. The new project will start with a kick-off meeting in the first half of 2021 (details to be announced).
Data available: 0.1° 1958-2018 ACCESS-OM2 IAF runs (plus extension to 2023)
Announcement (updated 20 March 2023):
Over 180Tb of model output data from COSIMA’s ACCESS-OM2-01 0.1-degree global coupled ocean – sea ice model is now available for anyone to use (see conditions below). This consists of four consecutive 61-year (1958-2018) cycles, with the 4th cycle including BGC and extended to 2023. This is part of a suite of control experiments at different resolutions, listed here.
Data access
We recommend using the COSIMA Cookbook to access and analyse this data, which is all catalogued in the default cookbook database. A good place to start is the data explorer, which will give an overview of the data available in this experiment (and many others).
Alternatively, the data can be directly accessed at NCI, mostly from
/g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf*
and with some (see details below) from
/g/data/ik11/outputs/access-om2-01/01deg_jra55v140_iaf_cycle3 and
/g/data/ik11/outputs/access-om2-01/01deg_jra55v140_iaf_cycle4_jra55v150_extension. You can find all the relevant ocean (but not sea ice) output files based on their names – e.g. this lists all the 3d daily-mean conservative temperature data in the first 0.1° IAF cycle: ls /g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf/output*/ocean/*-3d-temp-1-daily-mean-*.nc; the filenames also tell you the ending date.
You will need to be a member of the cj50 and ik11 groups to access this data directly or via the cookbook – apply at https://my.nci.org.au/mancini/project-search if needed.
The cj50 subset of the data (149TB) can be downloaded from here for those not on NCI.
Overview of experiment
The first cycle (01deg_jra55v140_iaf) was run under interannually-varying JRA55-do v1.4.0 forcing from 1 Jan 1958 to 31 Dec 2018, starting from rest with World Ocean Atlas 2013 v2 climatological temperature and salinity. The run configuration history is in the 01deg_jra55v140_iaf branch in the 01deg_jra55_iaf repository. It is based on that used for Kiss et al. (2020) but has many improvements to the forcing, initial conditions, parameters and code which will be documented soon. Summary details of each submitted run are tabulated (and searchable) here.
The second cycle (01deg_jra55v140_iaf_cycle2) continues from the end of the first cycle, with an identical configuration except that its initial condition was the final ocean and sea ice state of the first cycle, and some differences in the output variables. The run configuration history is in the 01deg_jra55v140_iaf_cycle2 branch and summary details of each submitted run are here.
Similarly, the third cycle (01deg_jra55v140_iaf_cycle3) continues from the end of cycle 2, with different output variables. The run configuration history is in the 01deg_jra55v140_iaf_cycle3 branch and summary details of each submitted run are here.
The fourth cycle (01deg_jra55v140_iaf_cycle4) and its extension are the only runs to contain biogeochemistry; this is mainly in the ocean, but also coupled to sea ice algae and nutrient. Cycle 4 continues from the end of cycle 3, with different output variables. Oxygen was initialised at 1 Jan 1979, and the remaining BGC tracers were initialised at 1 Jan 1958. BGC tracers have no effect on the physical state, and oxygen has no effect on other BGC tracers. The run configuration history is in the 01deg_jra55v140_iaf_cycle4 branch and summary details of each submitted run are here.
01deg_jra55v140_iaf_cycle4_jra55v150_extension extends cycle 4 (including BGC) from 1 Jan 2019 to the end of 2023, forced by JRA55-do v1.5.0 (2019 only) and v1.5.0.1 (1 Jan 2020 onwards) instead of v1.4.0. Diagnostics are the same as the end of cycle 4. The run configuration history is in the 01deg_jra55v140_iaf_cycle4_jra55v150_extension branch and summary details of each submitted run are here.
Further details on these runs are given in
/g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf*/metadata.yaml and
/g/data/ik11/outputs/access-om2-01/01deg_jra55v140_iaf_cycle4_jra55v150_extension/metadata.yaml.
There are many outputs available for the entirety of all cycles with additional outputs available only in particular cycles or years (see below for details).
MOM5 ocean model outputs are saved under self-explanatory filenames in
/g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf*/output*/ocean/*.nc
and CICE5 sea ice model outputs are in
/g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf*/output*/ice/OUTPUT/*.nc
(if there are too many files to list with ls, narrow it down, e.g. by including the year, e.g. *2000*.nc)
Annual restarts (on 1 Jan each year) are also available at
/g/data/ik11/restarts/access-om2-01/01deg_jra55v140_iaf*/restart*
for anyone who may wish to re-run a segment with different diagnostics or branch off a perturbation experiment.
Conditions of use:
We request that users of this or other COSIMA model code or output data:
-
- consider citing Kiss et al. (2020) [doi.org/10.5194/gmd-13-401-2020]
- include an acknowledgement such as the following:
The authors thank the Consortium for Ocean-Sea Ice Modelling in Australia (COSIMA; www.cosima.org.au), for making the ACCESS-OM2 suite of models available at github.com/COSIMA/access-om2. Model runs were undertaken with the assistance of resources from the National Computational Infrastructure (NCI), which is supported by the Australian Government. - let us know of any publications which use these models or data so we can add them to our list.
Details of model outputs available
Notes:
- You may find this partial list of diagnostics useful for decoding the MOM diagnostic names.
tempis conservative temperature, sosurface_temp,temp_surface_aveandbottom_tempare also conservative temperature, rather than the potential temperature specified in the OMIP protocol (Griffies et al., 2016) – see this discussion. If you need potential temperature, usepot_temporsurface_pot_temp.
⚠️ Errata:
- The
ty_trans_int_zdiagnostic was incorrect and has therefore been deleted from cycles 1 and 2. Workarounds are given here. - Some CICE sea ice data is incorrect – see this issue and this issue.
- Some tracer (e.g. BGC) flux and tendency diagnostics have incorrect units metadata.
- NPP data is actually phytoplankton growth minus grazing rather than net primary production.
wdet100was actually calculated at the surface, not 100m.- All non-6-hourly sea ice data in
01deg_jra55v140_iaf_cycle4is inconsistent with the ocean data from 2011-07-01 onwards; the 6-hourly ice area (2014-2016 inclusive) is inconsistent with the other sea ice variables, but consistent with the ocean.
Cycle 1 (66Tb): /g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf
- 1 Jan 1958 to 31 Dec 2018
- MOM ocean data
- Daily mean 2d bottom_temp, frazil_3d_int_z, mld, pme_river, sea_level, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, surface_salt, surface_temp
- Monthly mean 3d age_global, buoyfreq2_wt, diff_cbt_t, dzt, pot_rho_0, pot_rho_2, pot_temp, salt, temp_xflux_adv, temp_yflux_adv, temp, tx_trans, ty_trans_nrho_submeso, ty_trans_rho, ty_trans_submeso, ty_trans, u, v, vert_pv, wt
- Monthly mean 2d bmf_u, bmf_v, ekman_we, eta_nonbouss, evap_heat, evap, fprec_melt_heat, fprec, frazil_3d_int_z, lprec, lw_heat, melt, mh_flux, mld, net_sfc_heating, pbot_t, pme_net, pme_river, river, runoff, sea_level_sq, sea_level, sens_heat, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, sfc_salt_flux_coupler, sfc_salt_flux_ice, sfc_salt_flux_restore, surface_salt, surface_temp, swflx, tau_x, tau_y, temp_int_rhodz, temp_xflux_adv_int_z, temp_yflux_adv_int_z, tx_trans_int_z, wfiform, wfimelt
- Monthly mean squared 3d u, v
- Monthly max 2d mld
- Monthly min 2d surface_temp
- Daily snapshot scalar eta_global, ke_tot, pe_tot, rhoave, salt_global_ave, salt_surface_ave, temp_global_ave, temp_surface_ave, total_net_sfc_heating, total_ocean_evap_heat, total_ocean_evap, total_ocean_fprec_melt_heat, total_ocean_fprec, total_ocean_heat, total_ocean_hflux_coupler, total_ocean_hflux_evap, total_ocean_hflux_prec, total_ocean_lprec, total_ocean_lw_heat, total_ocean_melt, total_ocean_mh_flux, total_ocean_pme_river, total_ocean_river_heat, total_ocean_river, total_ocean_runoff_heat, total_ocean_runoff, total_ocean_salt, total_ocean_sens_heat, total_ocean_sfc_salt_flux_coupler, total_ocean_swflx_vis, total_ocean_swflx
- CICE sea ice data
- Daily mean 2d aice, congel, dvidtd, dvidtt, frazil, frzmlt, hi, hs, snoice, uvel, vvel
- Monthly mean 2d aice, alvl, ardg, congel, daidtd, daidtt, divu, dvidtd, dvidtt, flatn_ai, fmeltt_ai, frazil, frzmlt, fsalt, fsalt_ai, hi, hs, iage, opening, shear, snoice, strairx, strairy, strength, tsfc, uvel, vvel
- MOM ocean data
- 1 Jan 1987 to 31 Dec 2018 only
- MOM ocean data
- monthly mean 3d bih_fric_u, bih_fric_v, u_dot_grad_vert_pv
- daily mean 3d salt, temp, u, v, wt
- CICE sea ice data
- daily mean 2d aicen, vicen
- MOM ocean data
- 1 Jan 2012 to 31 Dec 2018 only
- MOM ocean data
- monthly snapshot 2d sea_level
- monthly snapshot 3d salt, temp, u, v, vert_pv and vorticity_z
- MOM ocean data
Cycle 2 (21Tb): /g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf_cycle2
- 1 Jan 1958 to 31 Dec 2018
- MOM ocean data
- Daily mean 2d bottom_temp, frazil_3d_int_z, mld, pme_river, sea_level, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, surface_salt, surface_temp
- Monthly mean 3d age_global, bih_fric_u, bih_fric_v, buoyfreq2_wt, diff_cbt_t, dzt, pot_rho_0, pot_rho_2, pot_temp, salt, temp_xflux_adv, temp_yflux_adv, temp, tx_trans, ty_trans_nrho_submeso, ty_trans_rho, ty_trans_submeso, ty_trans, u_dot_grad_vert_pv, u, v, vert_pv, wt
- Monthly mean 2d bmf_u, bmf_v, ekman_we, eta_nonbouss, evap_heat, evap, fprec_melt_heat, fprec, frazil_3d_int_z, lprec, lw_heat, melt, mh_flux, mld, net_sfc_heating, pbot_t, pme_net, pme_river, river, runoff, sea_level_sq, sea_level, sens_heat, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, sfc_salt_flux_coupler, sfc_salt_flux_ice, sfc_salt_flux_restore, surface_salt, surface_temp, swflx, tau_x, tau_y, temp_int_rhodz, temp_xflux_adv_int_z, temp_yflux_adv_int_z, tx_trans_int_z, wfiform, wfimelt
- Monthly mean squared 3d u, v
- Monthly max 2d mld
- Monthly min 2d surface_temp
- Daily snapshot scalar eta_global, ke_tot, pe_tot, rhoave, salt_global_ave, salt_surface_ave, temp_global_ave, temp_surface_ave, total_net_sfc_heating, total_ocean_evap_heat, total_ocean_evap, total_ocean_fprec_melt_heat, total_ocean_fprec, total_ocean_heat, total_ocean_hflux_coupler, total_ocean_hflux_evap, total_ocean_hflux_prec, total_ocean_lprec, total_ocean_lw_heat, total_ocean_melt, total_ocean_mh_flux, total_ocean_pme_river, total_ocean_river_heat, total_ocean_river, total_ocean_runoff_heat, total_ocean_runoff, total_ocean_salt, total_ocean_sens_heat, total_ocean_sfc_salt_flux_coupler, total_ocean_swflx_vis, total_ocean_swflx
- CICE sea ice data
- Daily mean 2d aice, congel, dvidtd, dvidtt, frazil, frzmlt, hi, hs, snoice, uvel, vvel
- Monthly mean 2d aice, aicen, alvl, ardg, congel, daidtd, daidtt, divu, dvidtd, dvidtt, flatn_ai, fmeltt_ai, frazil, frzmlt, fsalt, fsalt_ai, hi, hs, iage, opening, shear, snoice, strairx, strairy, strength, tsfc, uvel, vvel, vicen
- MOM ocean data
- 1 April 1971 to 31 Dec 2018 only
- CICE sea ice data
- Daily mean 2d fcondtop_ai, fsurf_ai, meltb, melts, meltt, daidtd, daidtt
- Monthly mean 2d fcondtop_ai, fsurf_ai, meltb, melts, meltt, fresh, dvirdgdt
- CICE sea ice data
- 1 April 1989 to 31 Dec 2018 only
- CICE sea ice data
- Daily mean 2d aicen, vicen
- CICE sea ice data
- 1 Oct 1989 to 31 Dec 2018 only
- MOM ocean data
- Daily max 2d surface_temp, bottom_temp, sea_level
- Daily min 2d surface_temp
- MOM ocean data
- 1 April 1990 to 31 Dec 2018 only
- MOM ocean data
- Daily mean 2d usurf, vsurf
- MOM ocean data
- 1 January 2014 to 31 Dec 2018 only
- MOM ocean data
- Daily mean, min, max 2d surface_pot_temp
- Monthly mean, min 2d surface_pot_temp
- CICE sea ice data
- Daily mean 2d sinz, tinz, divu
- Monthly mean 2d sinz, tinz, strocnx, strocny
- MOM ocean data
Cycle 3 (24 + 25 = 51Tb): mostly in /g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf_cycle3 but with some (marked in italics) in /g/data/ik11/outputs/access-om2-01/01deg_jra55v140_iaf_cycle3
- 1 Jan 1958 to 31 Dec 2018
- MOM ocean data
- Daily mean 3d salt, temp, uhrho_et, vhrho_nt (all but temp are at reduced precision and restricted to south of 60S)
- Daily mean 2d bottom_temp, frazil_3d_int_z, mld, pme_river, sea_level, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, surface_pot_temp, surface_salt, usurf, vsurf
- Monthly mean 3d age_global, buoyfreq2_wt, diff_cbt_t, dzt, passive_adelie, passive_prydz, passive_ross, passive_weddell, pot_rho_0, pot_rho_2, pot_temp, salt_xflux_adv, salt_yflux_adv, salt, temp_xflux_adv, temp_yflux_adv, temp, tx_trans_rho, tx_trans, ty_trans_nrho_submeso, ty_trans_rho, ty_trans_submeso, ty_trans, u, v, vert_pv, wt
- Monthly mean 2d bmf_u, bmf_v, ekman_we, eta_nonbouss, evap_heat, evap, fprec_melt_heat, fprec, frazil_3d_int_z, lprec, lw_heat, melt, mh_flux, mld, net_sfc_heating, pbot_t, pme_net, pme_river, river, runoff, sea_level_sq, sea_level, sens_heat, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, sfc_salt_flux_coupler, sfc_salt_flux_ice, sfc_salt_flux_restore, surface_pot_temp, surface_salt, swflx, tau_x, tau_y, temp_int_rhodz, temp_xflux_adv_int_z, temp_yflux_adv_int_z, tx_trans_int_z, ty_trans_int_z, wfiform, wfimelt
- Monthly mean squared 3d u, v
- Daily max 2d bottom_temp, sea_level, surface_pot_temp
- Daily min 2d surface_pot_temp
- Monthly max 2d mld
- Monthly min 2d surface_pot_temp
- Daily snapshot scalar eta_global, ke_tot, pe_tot, rhoave, salt_global_ave, salt_surface_ave, temp_global_ave, temp_surface_ave, total_net_sfc_heating, total_ocean_evap_heat, total_ocean_evap, total_ocean_fprec_melt_heat, total_ocean_fprec, total_ocean_heat, total_ocean_hflux_coupler, total_ocean_hflux_evap, total_ocean_hflux_prec, total_ocean_lprec, total_ocean_lw_heat, total_ocean_melt, total_ocean_mh_flux, total_ocean_pme_river, total_ocean_river_heat, total_ocean_river, total_ocean_runoff_heat, total_ocean_runoff, total_ocean_salt, total_ocean_sens_heat, total_ocean_sfc_salt_flux_coupler, total_ocean_swflx_vis, total_ocean_swflx
- CICE sea ice data
- Daily mean 2d aice, congel, daidtd, daidtt, divu, dvidtd, dvidtt, fcondtop_ai, frazil, frzmlt, fsurf_ai, hi, hs, meltb, melts, meltt, sinz, snoice, tinz, uvel, vvel
- Monthly mean 2d aice, aicen, alvl, ardg, congel, daidtd, daidtt, divu, dvidtd, dvidtt, dvirdgdt, fcondtop_ai, flatn_ai, fmeltt_ai, frazil, fresh, frzmlt, fsalt, fsalt_ai, fsurf_ai, hi, hs, iage, meltb, melts, meltt, opening, shear, sinz, snoice, strairx, strairy, strength, strocnx, strocny, tinz, tsfc, uvel, vvel, vicen
- MOM ocean data
- 1 Jan 1959 to 31 Mar 1963 only
- MOM ocean data
- Daily mean 3d passive_adelie, passive_prydz, passive_ross, passive_weddell
- MOM ocean data
- 1 Jan 2005 to 31 Dec 2018 only
- MOM ocean data
- Monthly mean 3d salt_xflux_adv, salt_yflux_adv
- MOM ocean data
- 1 July 2009 to 31 Dec 2018 only
- MOM ocean data
- Monthly mean 3d tx_trans_rho
- MOM ocean data
Cycle 4 (38Tb): /g/data/cj50/access-om2/raw-output/access-om2-01/01deg_jra55v140_iaf_cycle4
Includes coupled ocean and sea ice BGC. Note: 2d and 3d ocean BGC data has only 2 – 4 decimal digits of precision.
- 1 Jan 1958 to 31 Dec 2018
- MOM ocean physical data
- Daily mean 2d bottom_temp, frazil_3d_int_z, mld, pme_river, sea_level, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, surface_pot_temp, surface_salt, usurf, vsurf
- Monthly mean 3d age_global, buoyfreq2_wt, diff_cbt_t, dzt, pot_rho_0, pot_rho_2, pot_temp, salt_xflux_adv, salt_yflux_adv, salt, temp_xflux_adv, temp_yflux_adv, temp, tx_trans_rho, tx_trans, ty_trans_nrho_submeso, ty_trans_rho, ty_trans_submeso, ty_trans, u, v, vert_pv, wt
- Monthly mean 2d bmf_u, bmf_v, ekman_we, eta_nonbouss, evap_heat, evap, fprec_melt_heat, fprec, frazil_3d_int_z, lprec, lw_heat, melt, mh_flux, mld, net_sfc_heating, pbot_t, pme_net, pme_river, river, runoff, sea_level_sq, sea_level, sens_heat, sfc_hflux_coupler, sfc_hflux_from_runoff, sfc_hflux_pme, sfc_salt_flux_coupler, sfc_salt_flux_ice, sfc_salt_flux_restore, surface_pot_temp, surface_salt, swflx, tau_x, tau_y, temp_int_rhodz, temp_xflux_adv_int_z, temp_yflux_adv_int_z, tx_trans_int_z, ty_trans_int_z, wfiform, wfimelt
- Monthly mean squared 3d u, v
- Monthly max 2d mld
- Monthly min 2d surface_pot_temp
- Daily max 2d bottom_temp, sea_level, surface_pot_temp
- Daily min 2d surface_pot_temp
- Daily snapshot scalar eta_global, ke_tot, pe_tot, rhoave, salt_global_ave, salt_surface_ave, temp_global_ave, temp_surface_ave, total_net_sfc_heating, total_ocean_evap_heat, total_ocean_evap, total_ocean_fprec_melt_heat, total_ocean_fprec, total_ocean_heat, total_ocean_hflux_coupler, total_ocean_hflux_evap, total_ocean_hflux_prec, total_ocean_lprec, total_ocean_lw_heat, total_ocean_melt, total_ocean_mh_flux, total_ocean_pme_river, total_ocean_river_heat, total_ocean_river, total_ocean_runoff_heat, total_ocean_runoff, total_ocean_salt, total_ocean_sens_heat, total_ocean_sfc_salt_flux_coupler, total_ocean_swflx_vis, total_ocean_swflx
- WOMBAT ocean BGC data
- Monthly mean 3d adic, alk, caco3, det, dic, fe, no3, o2, phy, zoo
- Monthly mean 2d npp2d, pprod_gross_2d, stf03, stf07, stf09, wdet100
- Daily snapshot scalar total_aco2_flux, total_co2_flux
- CICE sea ice data
- Daily mean 2d aice, congel, daidtd, daidtt, divu, dvidtd, dvidtt, fcondtop_ai, frazil, frzmlt, fsurf_ai, fswthru_ai, hi, hs, meltb, melts, meltt, snoice, uvel, vvel
- Monthly mean 2d aice, aicen, alidf_ai, alidr_ai, alvdf_ai, alvdr_ai, alvl, ardg, bgc_n_sk, bgc_nit_ml, bgc_nit_sk, congel, daidtd, daidtt, divu, dvidtd, dvidtt, dvirdgdt, fcondtop_ai, flatn_ai, fmeltt_ai, fn_ai, fno_ai, frazil, fresh, frzmlt, fsalt, fsalt_ai, fsurf_ai, fswthru_ai, fswup, hi, hs, iage, meltb, melts, meltt, opening, ppnet, shear, snoice, strairx, strairy, strength, strocnx, strocny, tsfc, uvel, vicen, vvel
- MOM ocean physical data
- 1 Jan 1958 to 31 Oct 1959 and 1 Jan 2014 to 31 Dec 2016 only
- CICE sea ice data
- Daily mean 2d sinz, tinz
- Monthly mean 2d sinz, tinz
- CICE sea ice data
- 1 April 1975 to 31 Dec 2018 only
- CICE sea ice data
- Monthly mean 2d meltl
- CICE sea ice data
- 1 January 1979 to 31 Dec 2018 only
- WOMBAT ocean BGC data
- Daily mean 3d, sampled every 5 days (but a possible jump 1 Jan 2016) adic, dic, fe, no3, o2, phy
- Daily mean 2d adic_int100, adic_intmld, det_int100, det_intmld, dic_int100, dic_intmld, fe_int100, fe_intmld, no3_int100, no3_intmld, npp_int100, npp_intmld, npp1, npp2d, o2_int100, o2_intmld, paco2, pco2, phy_int100, phy_intmld, pprod_gross_2d, pprod_gross_int100, pprod_gross_intmld, radbio_int100, radbio_intmld, radbio1, stf03, stf07, stf09, surface_adic, surface_alk, surface_caco3, surface_det, surface_dic, surface_fe, surface_no3, surface_o2, surface_phy, surface_zoo, wdet100
- Monthly mean 3d adic_xflux_adv, adic_yflux_adv, adic_zflux_adv, caco3_xflux_adv, caco3_yflux_adv, caco3_zflux_adv, det_xflux_adv, det_yflux_adv, det_zflux_adv, dic_xflux_adv, dic_yflux_adv, dic_zflux_adv, fe_xflux_adv, fe_yflux_adv, fe_zflux_adv, no3_xflux_adv, no3_yflux_adv, no3_zflux_adv, npp3d, o2_xflux_adv, o2_yflux_adv, o2_zflux_adv, pprod_gross, radbio3d, src01, src03, src05, src06, src07, src09, src10
- WOMBAT ocean BGC data
- 1 January 1987 to 31 Dec 2018 only
- CICE sea ice data
- Daily mean 2d albsni, fhocn_ai, fswabs_ai, dardg2dt, bgc_n_sk, bgc_nit_sk, ppnet
- Monthly mean 2d albsni, fhocn_ai, fswabs_ai, dardg2dt
- CICE sea ice data
- 1 Jan 2014 to 31 Dec 2016 only
- MOM ocean physical data
- 6-hourly mean 2d mld, surface_pot_temp, surface_salt
- WOMBAT ocean BGC data
- 6-hourly mean 2d radbio1, surface_fe, surface_no3, surface_o2, surface_phy
- CICE sea ice data
- 6-hourly mean 2d aice
- Daily mean 2d alidf_ai, alidr_ai, alvdf_ai, alvdr_ai, fswup
- MOM ocean physical data
- 1 Jan 2016 to 31 Dec 2016 only
- CICE sea ice data
- 3-hourly mean 2d divu, shear, uvel, vvel
- Daily mean 2d aicen, vicen
- CICE sea ice data
Cycle 4 2019-2023 extension, using JRA55-do v1.5.0 for 2019, and JRA55-do v1.5.0.1 to the end of 2023 (6.6Tb): /g/data/ik11/outputs/access-om2-01/01deg_jra55v140_iaf_cycle4_jra55v150_extension. Outputs are the same as the end of cycle 4.
COSIMA Model Output Collection
An increasingly important aspect of model simulations is to be able to share our data. Over the last few years we have been working on methods to routinely publish our most important simulations. This publication process is designed to allow any users, worldwide, to be able to pick up our model output and test hypotheses against our results. It will also allow journal publications to be able to cite our model output.
Currently we have 5 different datasets within the headline COSIMA Model Output Collection, which can be found here:
http://dx.doi.org/10.4225/41/5a2dc8543105a
For users with NCI access this data is housed under the cj50 project.
We are planning to add new datasets in the coming months.
SAMx paper submitted
The Southern Ocean has accounted for the vast majority of the global ocean heat uptake since the early 2000s. The atmospheric winds over the Southern Ocean play a leading role in its ability to uptake heat, by way of driving much of the Southern Ocean circulation. Observations of these winds indicate that they have been steadily changing over the past few decades, and hence, so too is the Southern Ocean heat uptake. However, despite recent research efforts, the details of the Southern Ocean’s response to these changing winds remain uncertain.
In a recently submitted paper, we introduce a novel methodology to examine the Southern Ocean’s response to changing winds. We perform numerical simulations with the COSIMA model suite at all three resolutions and driven by realistic atmospheric forcing conditions. Our novel approach requires us to characterise the dynamical differences between our various realistic forcing conditions, which we do so with a new simple diagnostic. This new diagnostic proves robust in predicting the rapid response of the Southern Ocean circulation to the changing winds.
“Response of the Southern Ocean overturning circulation to extreme Southern Annular Mode conditions“; Stewart, Hogg, England & Waugh, Submitted to Geophysical Research Letters.
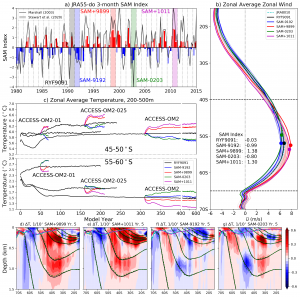
Figure: a) Three-monthly SAM index calculated from the JRA55-do dataset; solid bars indicate the Austral summer quarters (September-February, inclusive). The four SAMx periods are shaded, as well as the RYF9091. For comparison, the equivalent observation station-based SAM index of Marshall (2003) is included in black. b) Zonal average zonal winds for the SAMx and RYF9091 periods, with the location of the respective peaks indicated by the circles. Also included is the 1980–2010 average of the JRA55-do dataset (dashed cyan), and all remaining May–April periods between 1980–2015 coloured blue–red by their respective SAM index. c) Timeseries of the zonal average temperatures between 200–500m depth for 45–50S (upper) and 55–60S (lower); these latitudinal bands are selected to lie either side of the zonal wind speed maximum evident in (b). Distributions of the Year 5 temperature anomalies from the ACCESS-OM2-01 for (d) SAM+9899, (e) SAM+1011, (f) SAM-9192 and (g) SAM-0203 simulations. The black and dashed green contours represent the SAMx and RYF9091 isopycnals at 0.5kg/m3 intervals, respectively, with the cyan and dashed magenta contours representing the respective mixed-layer depths.
Updated COSIMA Cookbook default database
The COSIMA Cookbook is the recommended, and supported, method for finding and accessing COSIMA datasets.
Currently COSIMA datasets are located in temporary storage under the hh5 project on the /g/data filesystem at NCI. The default COSIMA Cookbook database (/g/data/hh5/tmp/cosima/database/access-om2.db) indexes data in this location.
The COSIMA datasets are being moved to a new project, ik11: dedicated storage provided by an ARC LIEF grant. As part of this transition the default database will change to:
/g/data/ik11/databases/cosima_master.db
and will index all data in /g/data/ik11/outputs/. The database is updated daily.
This change will take place from Wednesday the 1st of July. To access the old database pass an argument to create_session:
session = cc.database.create_session(db='/g/data/hh5/tmp/cosima/database/access-om2.db')
or set the COSIMA_COOKBOOK_DB environment variable, e.g. for bash
export set COSIMA_COOKBOOK_DB=/g/data/hh5/tmp/cosima/database/access-om2.db
In the same way the new ik11 database can be accessed by using the path to it (/g/data/ik11/databases/cosima_master.db) in the same manner as above.